Most software gets tested when organizations decide to change it. SAP Integrated Business Planning works the other way around: SAP changes it for you, four times a year, whether your team is ready or not. That one fact reshapes everything about SAP IBP testing, — who owns it, when it happens, and what breaks when it gets skipped.
This guide approaches SAP IBP testing from a quality assurance angle: what makes IBP different from other SAP applications, the five layers every test strategy needs, how to plan around the quarterly release cycle, and the pitfalls that catch experienced teams. One clarification up front, if you searched this term looking for certification prep, this is not exam content. This guide is for teams responsible for keeping a live IBP environment stable.
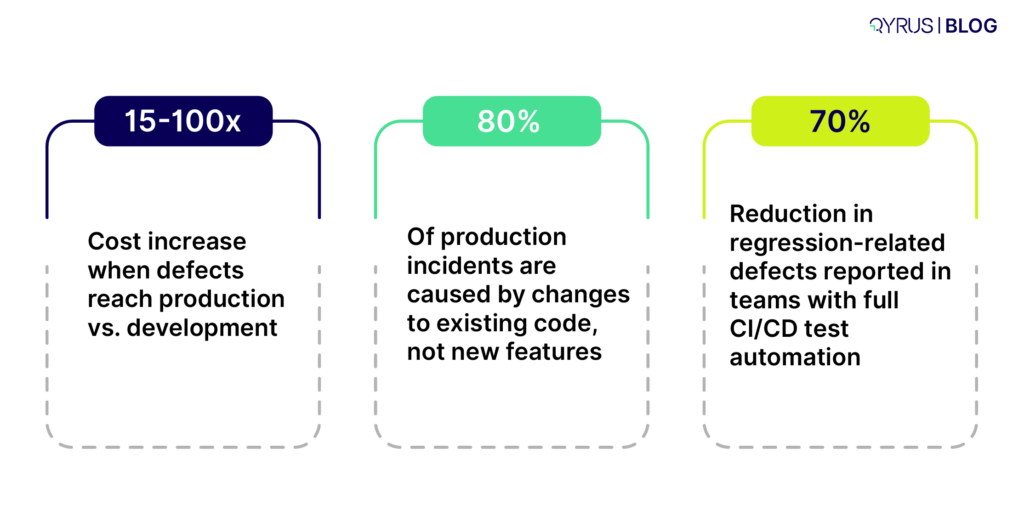
The stakes are real. IBP sits at the center of demand planning, supply planning, inventory optimization, and sales and operations planning (S&OP) for more than 1,000 companies worldwide. When a key figure is calculated incorrectly or a data load silently corrupts planning data, planners make real decisions on wrong numbers. In a period when 94% of companies reported revenue damage from supply chain disruptions, the planning platform is the last place you want silent defects.
Why SAP IBP Testing Is Different From Classic SAP Testing
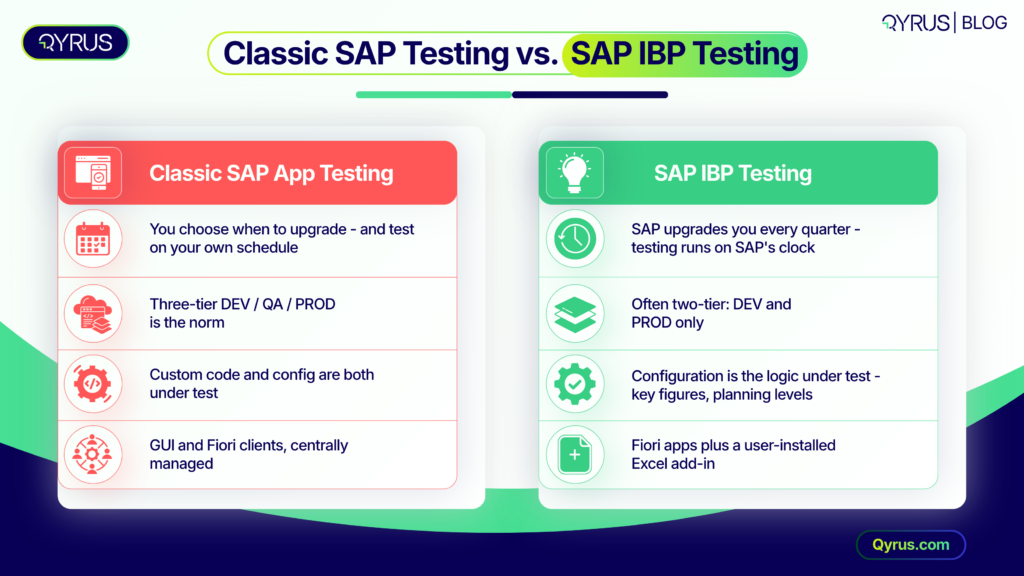
Teams arriving at IBP from ECC or S/4HANA testing often assume the same playbook applies. Four structural differences say otherwise.
You do not control the release calendar. IBP is a cloud-only product, and quarterly updates add functionality but also require testing of the changed features once each update completes. There is no option to defer an upgrade for a year while you prepare. The release lands, and your configuration either still works or it does not.
The platform keeps evolving underneath you. The 2508 release introduced I_SAPIBP2, a new unified planning area that combines time-series and order-based planning data, with initial solution content delivered in release 2511. Structural changes of this size can quietly invalidate assumptions baked into your planning views, custom key figures, and integration jobs.
Your test environment options are thinner. Many SAP-provided IBP setups are two-tier — development and production — and a single test system limits your ability to verify bug fixes before they reach production, especially when several projects overlap on the same tenant. Some organizations now add a third tenant purely to separate testing from ongoing configuration work.
The primary user interface lives in Excel. Planners spend most of their day in the SAP IBP add-in for Microsoft Excel. A new add-in version ships with every IBP release, and customers are responsible for rolling it out to individual users. Client-side version drift is a genuine test dimension that most web-application test strategies never consider.
There is a fifth, quieter difference: planning logic in IBP is configuration, not code. Key figures, planning levels, attributes, and calculation chains are all configured. “Unit testing” in IBP means validating configured calculation logic against expected results, not reviewing custom ABAP.
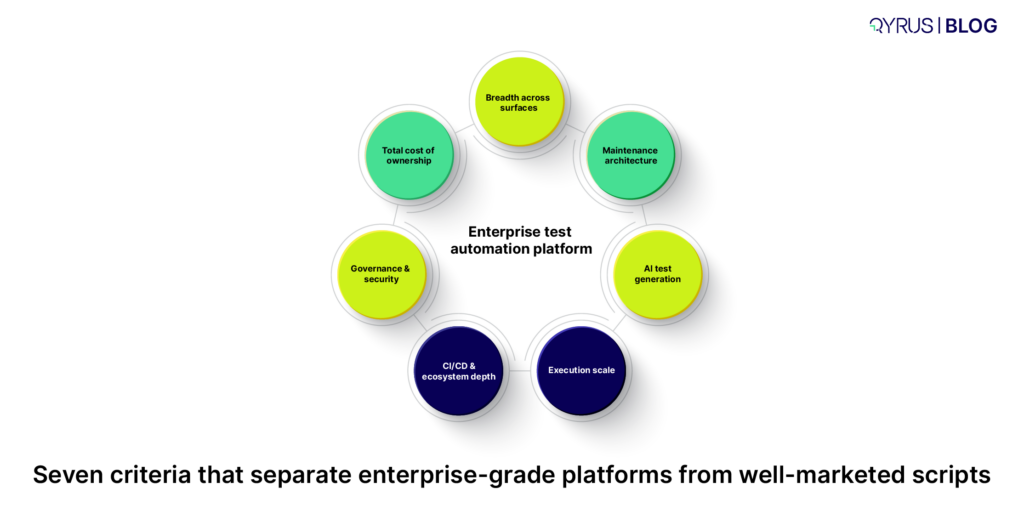
The Five Layers of SAP IBP Testing
A workable IBP test strategy covers five distinct layers. Each one fails in a different way, so none of them can substitute for another.

- Planning Model Validation
This is the IBP equivalent of unit testing. Verify that each key figure calculates correctly at its base planning level, that aggregation and disaggregation behave as designed across levels, and that planning versions and scenarios stay isolated from the baseline. The reliable method is a small, controlled dataset with expected outputs computed independently — in a spreadsheet, with calculations performed independently by a functional consultant and compared against what the model produces. If the numbers match at the lowest level and after aggregation, the model is sound. Pay particular attention to disaggregation rules, currency and unit-of-measure conversions, and time-profile boundaries such as week-to-month splits, because these are the places where a calculation can be right in one view and wrong in another.
- Data Integration Testing
IBP receives master data and transactional data through Cloud Integration for Data Services (CI-DS), Real-Time Integration (RTI) for order-based planning, or SAP Cloud Integration. The biggest trap is deceptively simple: a green job status means the load ran, not that the data is right. Experienced IBP practitioners push teams to confirm that data transformation worked correctly across all records within CI-DS, and to build target data integrity checks that catch issues before business users do. Reconcile record counts and key figure totals between source and target on every critical interface. This is the same class of problem as the “green light lie” in IDoc and EDI processing, which we covered in our guide to uncovering SAP IDoc/EDI mapping issues.
- Functional Testing and UAT
Functional testing validates planner workflows end to end: running a statistical forecast, reviewing results in a planning view, adjusting a consensus demand figure, releasing a plan to supply. SAP’s own implementation guidance assigns unit and integration testing to the implementation team and puts user acceptance testing in the hands of business users — ideally the same planners who joined the design workshops. UAT should exercise both the Fiori apps and the Excel add-in, because planners will use both in production. For a deeper structure on running this phase well, see our guide to SAP user acceptance testing.
- Regression Testing for Quarterly Releases
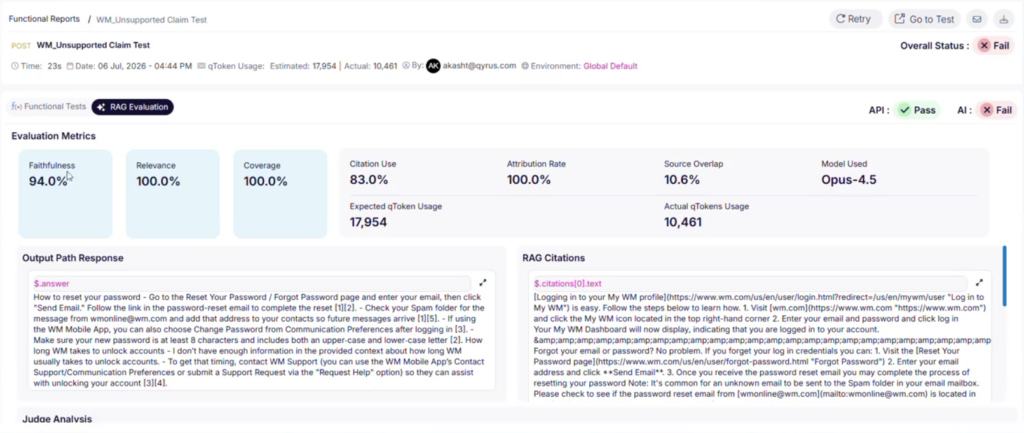
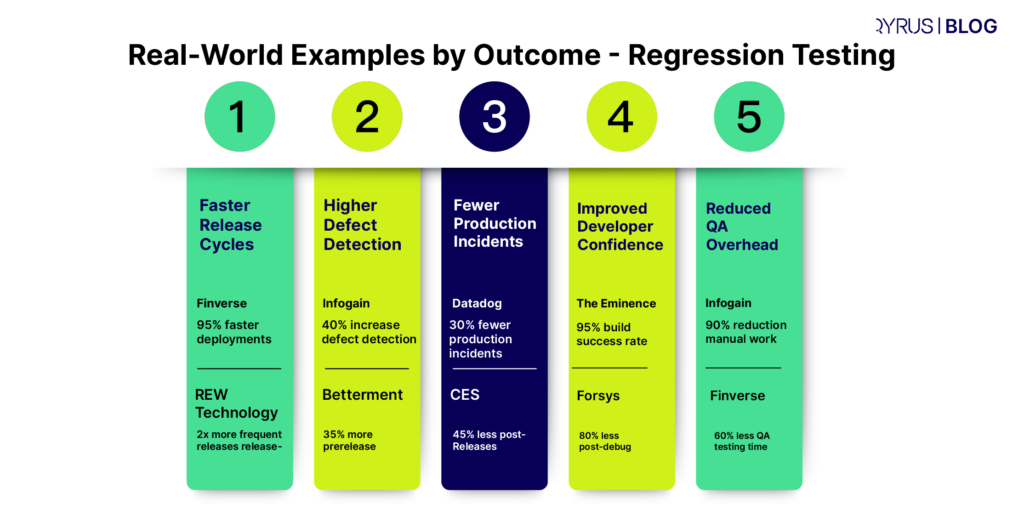
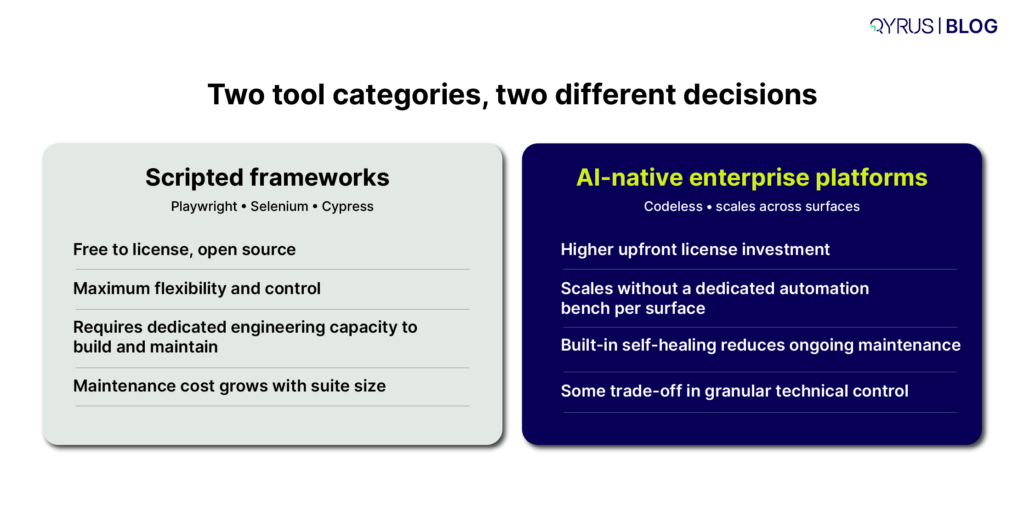
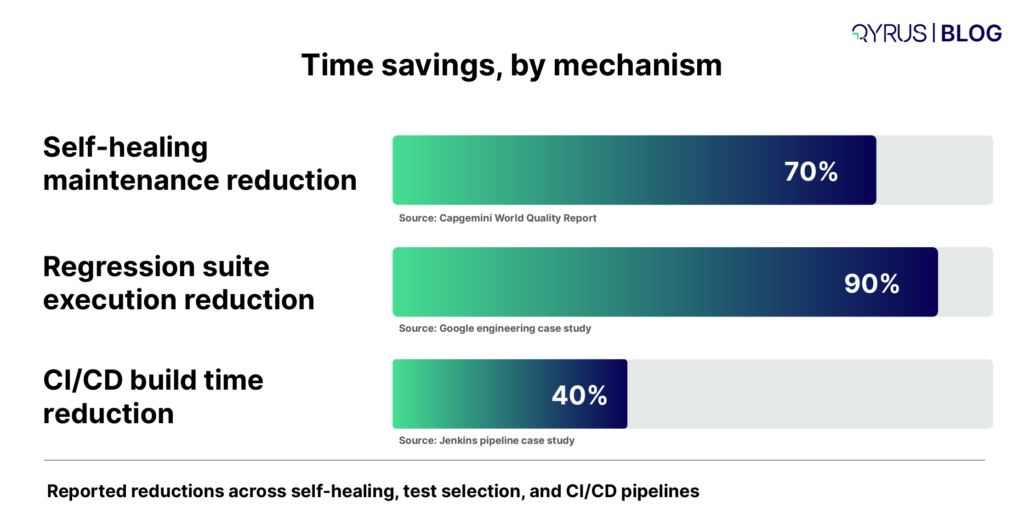
This layer is where IBP differs most from on-premise SAP. Every quarter, you need confidence that your existing configuration still works on the new release. SAP provides a Regression Test Service for SAP IBP that tests customer-specific configuration and reduces upgrade test effort, and it is worth evaluating — but its scope is defined by SAP, not by your risk profile. Custom planning views, integration chains, and any process spanning IBP and other systems remain your responsibility. Teams that automate this recurring core stop paying the same manual cost four times a year; our article on AI-driven SAP regression testing covers how that shift works in practice.
- Performance Testing
Planning runs, batch jobs, and data loads all operate within defined time windows, — a supply planning run that finishes at 6 a.m. instead of 2 a.m. breaks the planner’s morning. Track planning run durations and batch window fit release over release, and re-test whenever data volumes grow or the planning model changes materially. The discipline mirrors what we describe in our complete guide to SAP performance testing, applied to IBP’s job-centric workload.

Building a Test Strategy Around the Quarterly Release Cycle
Because the release cadence is fixed, the smartest move is to stop treating each upgrade as a project and start treating testing as a calendar-driven operating rhythm.
- Anchor your test calendar to SAP’s release schedule. Test tenants receive each release before production. That preview window is your regression slot — plan for it in advance, every quarter, with named owners.
- Scope by risk, not by the pursuit of complete coverage
- . Read the release notes against your own configuration and test what changed. Add what is critical — the steps of your S&OP cycle that feed real decisions — and what is complex, such as multi-level key figure chains and order-based planning integration.
- Maintain a golden dataset. Keep a stable, versioned set of master data and key figure inputs with known expected outputs. Run it before and after every upgrade. Without a baseline, you cannot tell a release defect from a data change.
- Decide your environment strategy deliberately. If you run on a two-tier setup, define how test data gets refreshed, who owns the test tenant during the preview window, and how you keep configuration-in-progress separate from upgrade validation. Organizations running several parallel IBP projects increasingly justify a third tenant for exactly this reason — it converts a scheduling conflict into a standing capability.
- Automate the recurring core. An ASUG and Worksoft study found that 79% of SAP customers using test automation reduced manual and low-tier work, while 75% of SAP customers still run special hyper-care periods after SAP updates. A quarterly cadence is exactly the pattern automation exists to absorb.
Handled this way, the quarterly release stops being a fire drill. It becomes a known, bounded event with a fixed test scope and a predictable cost.

Common SAP IBP Testing Pitfalls
Trusting green statuses. Load jobs, planning runs, and application jobs all report technical success independently of business correctness. Validate outcomes, not statuses.
Testing without a baseline. If master data drifts freely in your test tenant, every comparison becomes ambiguous. Snapshot your test data, version it, and refresh it deliberately.
Validating only at aggregate level. A total that looks right can hide disaggregation errors underneath. Spot-check the base planning level, not just the summary view planners see first.
Treating UAT as training. If business users first touch the system during UAT, you get a training session with a sign-off form. UAT verifies decisions made at design time; training belongs earlier and separately.
Ignoring the Excel add-in matrix. Add-in versions, Office versions, and IBP releases interact. A planner on an old add-in can hit defects nobody reproduced in testing. Include the client version matrix in your regression scope, and factor it into tooling decisions when you choose an SAP testing platform.
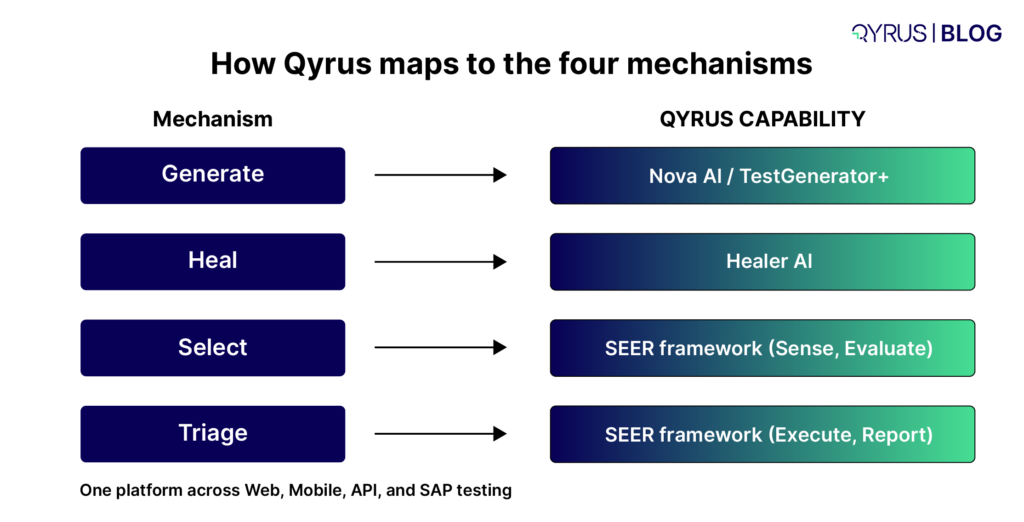
How Qyrus Helps With SAP IBP Testing
Qyrus is an AI-powered, codeless testing platform with dedicated SAP testing capabilities, built for exactly the recurring-validation pattern that IBP’s quarterly cycle creates.
- UI5-aware test automation. IBP’s browser applications are built on SAP Fiori/UI5. Qyrus’s recorder detects Fiori/UI5 controls natively, avoiding the brittle XPath locators that make SAP UI automation expensive to maintain and staying resilient as SaaS interfaces change.
- The 3 Cs scoping framework. Qyrus structures SAP test strategy around what is Critical, Complex, and Changed — a direct fit for scoping each quarterly IBP release instead of re-testing everything.
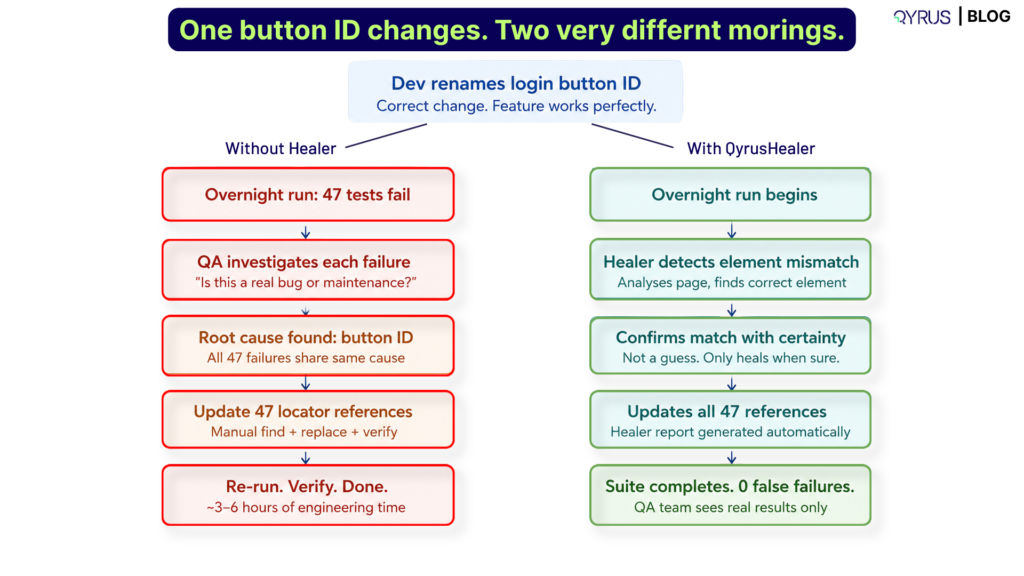
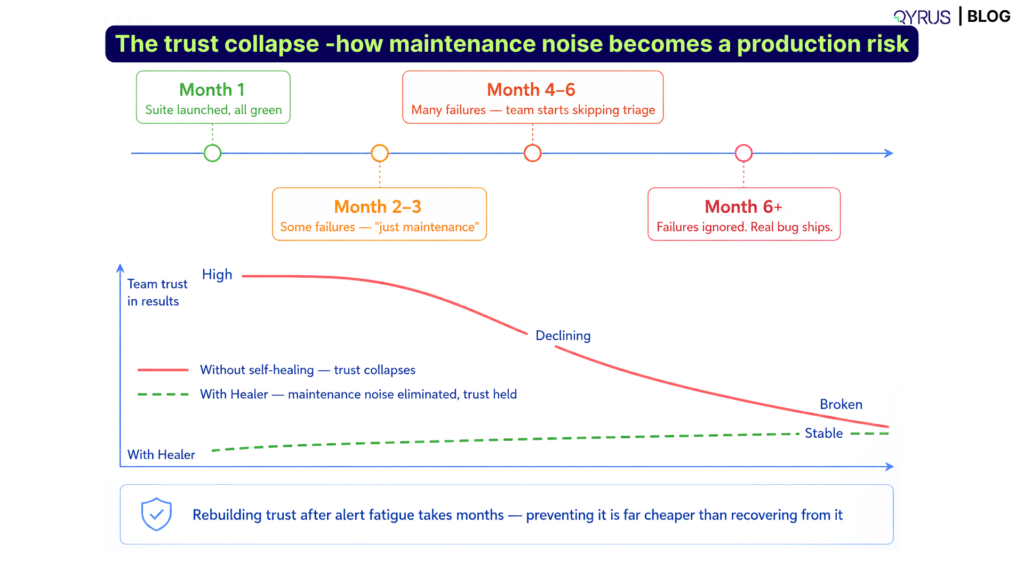
- Self-healing scripts. When a UI update breaks a locator, Qyrus’ Healer references a passing baseline and suggests corrected locators, cutting the maintenance tax that normally kills SAP automation programs at cloud release speed.
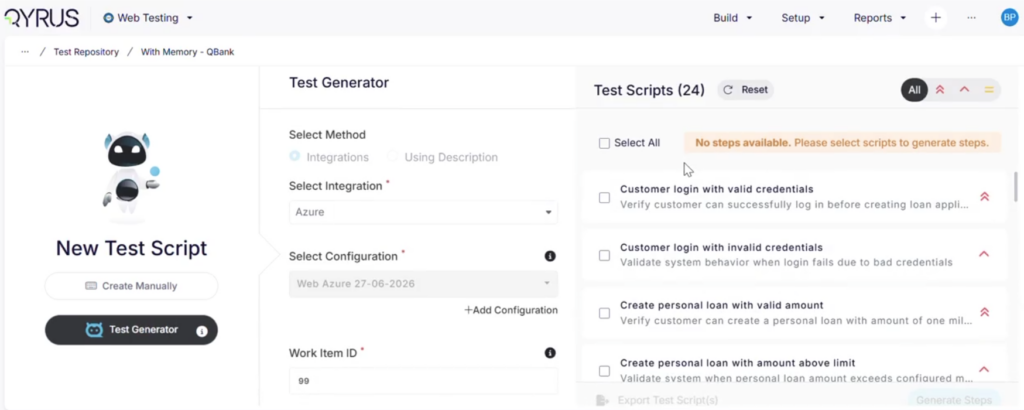
- Codeless test building. Functional consultants and business analysts who understand planning processes can build and maintain tests without writing automation code, which keeps IBP process knowledge and test ownership in the same hands.
The results pattern is established in SAP environments: a North American Coca-Cola bottler cut testing effort by 88% on a critical SAP process using Qyrus automation. Across the platform, a Forrester Total Economic Impact study of Qyrus found a 213% return on investment with a payback period under six months, driven in part by a 70% reduction in test building time.
Frequently Asked Questions About SAP IBP Testing
What is SAP IBP testing?
SAP IBP testing is the validation of an SAP Integrated Business Planning environment across five layers: planning model logic, data integration, functional planner workflows, regression after quarterly releases, and performance of planning runs and batch jobs.
How often does SAP IBP need regression testing?
At minimum once per quarter, aligned to SAP’s release cycle. Test tenants receive each release ahead of production, and that window is the natural slot for the regression pass. Additional regression is needed after significant configuration or integration changes.
Who should perform SAP IBP UAT?
Business planners and process owners — ideally the people who participated in design workshops. The implementation or QA team handles unit and integration testing; UAT exists to confirm the system supports real planning work, which only business users can judge.
Can SAP IBP testing be automated?
Yes, and the quarterly cadence makes automation unusually valuable. Browser-based Fiori workflows and data validation checks are strong automation candidates. Manual effort is better reserved for exploratory testing and business judgment during UAT.
What is the SAP Regression Test Service for IBP?
An SAP-provided service that tests customer-specific IBP configuration to reduce the effort associated with quarterly upgrades. It is a useful component, but its scope is SAP-defined — custom views, integrations, and cross-system processes still need your own regression coverage.
Turn the Quarterly Upgrade into a Non-Event
SAP IBP rewards teams that treat testing as a standing capability rather than a scramble. Build your strategy around these five layers, anchor your calendar to the release cycle, keep a golden dataset, and automate the regression core you will otherwise repeat by hand four times a year. Do that, and the quarterly release becomes what it should be: routine.
Qyrus brings codeless, self-healing SAP test automation to that rhythm, so planning teams keep their confidence without growing their testing headcount. Request a demo to see how Qyrus can help you keep every IBP release stable without the quarterly fire drill.