The problem is not building tests. It is keeping them alive. Here’s a scenario I’ve seen repeatedly.
A conversation that is happening right now on my Slack
“Half the tests in the overnight run have failed”.
“Is the feature broken?”
“No — dev updated the button ID on the login screen. Now every test that passes through login is broken.”
“How long to fix?”
“Probably a day. Maybe two if there are other changes we haven’t found yet.”
Typing…..
This is not a staffing problem, nor is it a process problem. It is a structural problem with how test automation works — and it has been getting worse every year as delivery cycles shorten, UI updates accelerate, and test suites grow larger.
The question teams are searching for answers to is not ‘how do we write better tests.’ It is, “Why do our tests keep breaking when nothing is actually wrong with the application, and what do we do about it?”
The Qyrus guide covers that question specifically: what causes test maintenance to consume the majority of QA engineering time, why the problem compounds as suites scale, and how AI-powered self-healing can potentially change the economics of automation maintenance.
The Test Maintenance Problem Has Gotten Worse Since 2023
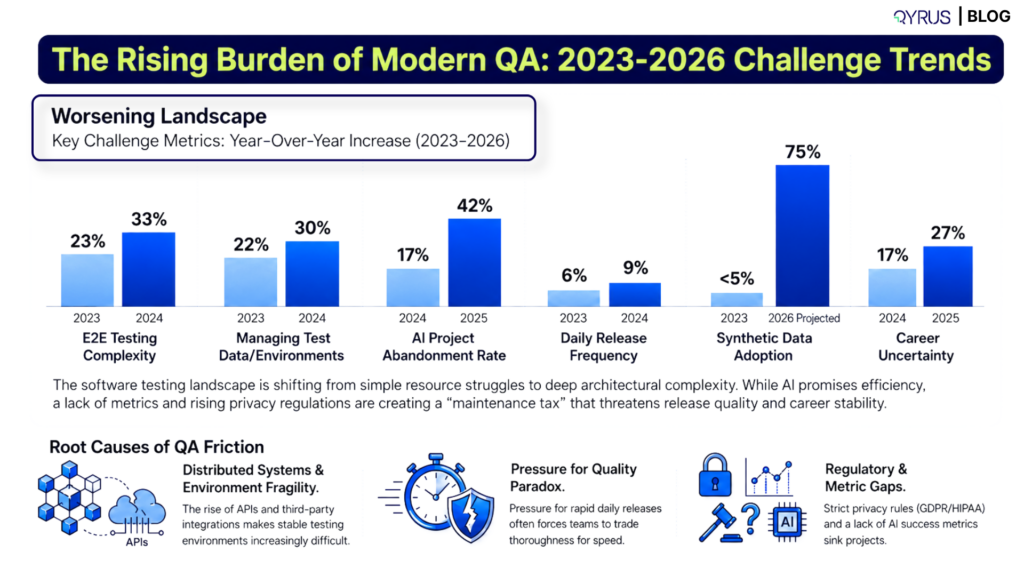
Test maintenance has always been a cost of automation. Teams have always had to update scripts when the application changes. What changed between 2023 and now is the rate of change — and the gap between how fast applications ship and how fast QA teams can keep up with the resulting breakage.
What Actually Breaks Tests? It’s More Than Bugs
This is the part that most teams find frustrating when they first audit where their maintenance time goes. The majority of test failures in a mature automation suite are not catching real defects. They are responding to cosmetic and structural changes in the application that have nothing to do with whether the feature works:
Element ID or class name changes — a developer renames a CSS class or button ID as part of a refactor. Every test that references the old identifier breaks, even though the button still works exactly the same way
Layout and position shifts — a component moves to a different location on the page, or its position in the DOM changes. Tests that used XPath selectors based on element position now point at the wrong element
Label and copy updates — a button label changes from ‘Submit’ to ‘Continue’. Tests that matched on visible text now fail
Third-party component upgrades — a UI library version bump changes how components render internally, breaking selectors that referenced internal library element IDs
Environment-specific rendering differences — the same element renders differently in staging vs. production, or across browser versions, causing tests to pass in one environment and fail in another
The Statistic That Explains the Test Maintenance Problem
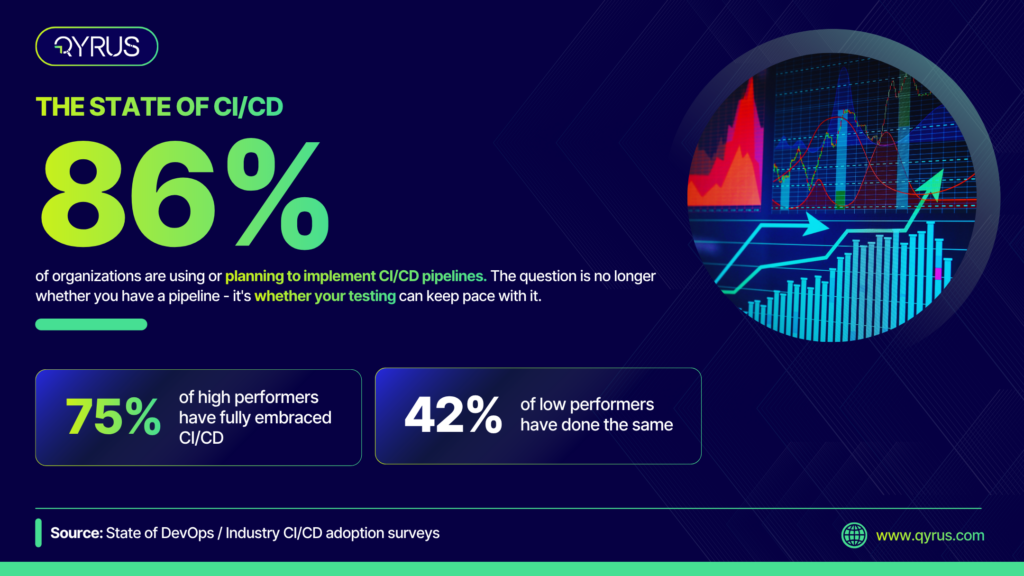
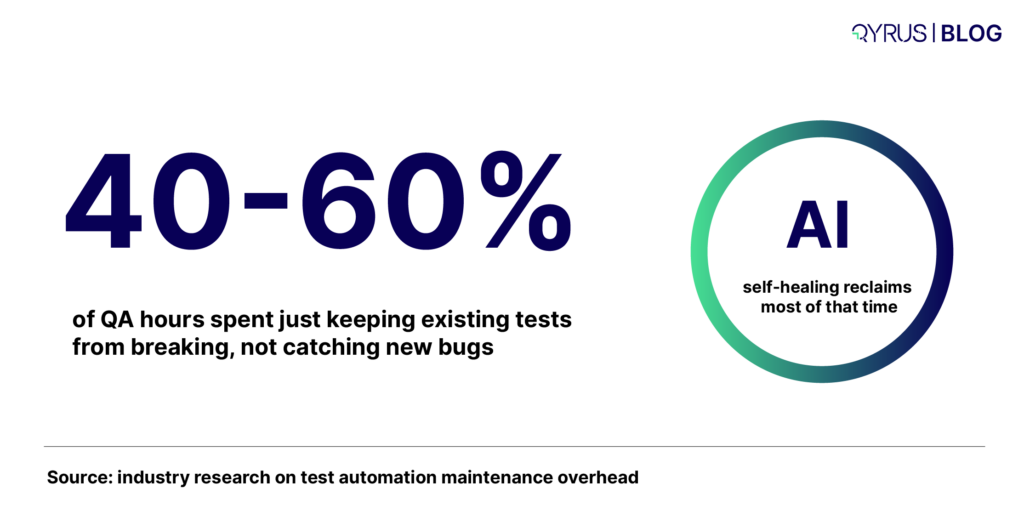
Our research across enterprise QA departments consistently finds that 35 to 40 percent of QA engineering time goes to maintaining test scripts that break due to application changes — not to finding or preventing defects. In a team of ten QA engineers, three to four of them are effectively working full-time on keeping existing tests alive. That is before any new test creation, strategy work, or exploratory testing.
Why the problem compounds as suites grow
The maintenance burden does not scale linearly with the size of the test suite. It scales faster. A suite of 500 tests is not five times harder to maintain than a suite of 100 — it is closer to ten times harder, for three reasons:
- Shared element references multiply breakage- when a navigation element that appears on every page changes, it does not break one test. It breaks every test that touches any page with that element. One change can cascade into dozens of failures across unrelated test cases
- Failure triage gets slower- in a small suite, finding the root cause of a failure is fast. In a large suite, a single underlying change can produce hundreds of distinct failure messages, each pointing at a different test case, each requiring individual investigation to confirm they share the same root cause
- Prioritization becomes impossible- when every run produces dozens of failures, teams lose the ability to distinguish between a failure that represents a real defect and a failure that represents a stale selector. Eventually, engineers start treating all failures as noise and stop investigating which is exactly the opposite of what automation is supposed to achieve
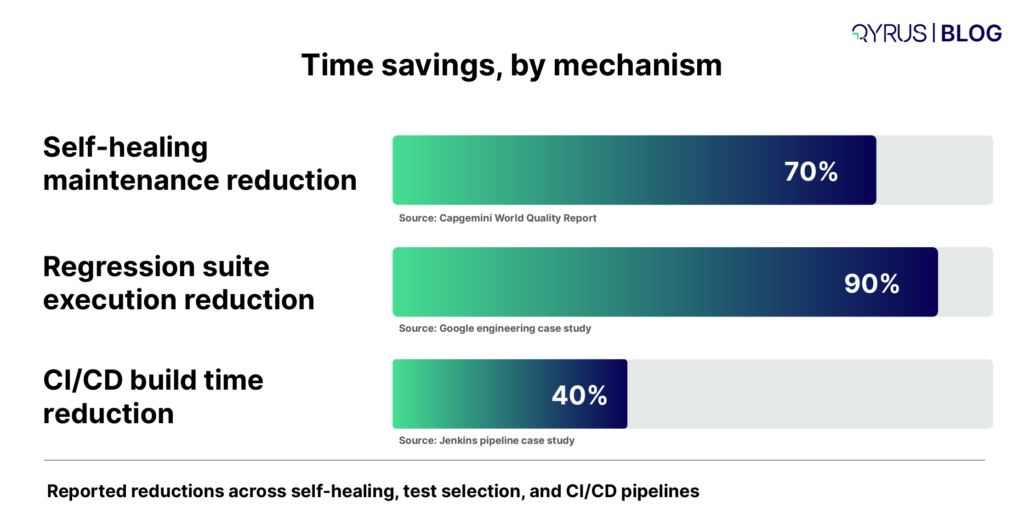
The data reflects the same pattern. Capgemini’s World Quality Report finds that 30–40% of QA engineering time is spent on test maintenance rather than defect detection. Research on AI self-healing frameworks suggests that maintenance effort can be reduced by 40–60%.
Real-world adoption is starting to show similar results: Peloton reported a 78% reduction in test maintenance after deploying AI-powered testing in 2025, saving more than 30 hours per month.
What teams have tried — and why it only partially works
Most QA teams have already tried to address the maintenance problem before reaching for AI. The standard approaches have real limitations:
- Switching to more stable selectors — teams move from brittle XPath selectors to data-testid attributes or aria labels, which are more intentional and less likely to break on cosmetic changes. This helps, but it requires developer cooperation on every new feature, and it does not help for third-party components or applications where adding test attributes is not possible
- Page object models — abstracting element references into a single layer reduces the number of places that need updating when an element changes. But it still requires manual updates — it just consolidates where those updates happen
- Reducing test scope — some teams respond to mounting maintenance costs by simply running fewer tests, deprioritising coverage of UI-heavy flows. This reduces maintenance work by reducing what there is to maintain, but it also reduces coverage and reintroduces the defect risk that automation was supposed to prevent
None of these approaches address the root cause. They manage the maintenance burden more efficiently — they do not eliminate it.
How AI Self-Healing Changes the Economics of Test Maintenance
AI self-healing does not work by writing better selectors or by requiring developers to add test attributes. It works by teaching the automation layer to recover from element changes on its own, without human intervention.
What self-healing actually does — specifically
When a traditional automated test runs and cannot locate an element — because the ID changed, or the class was renamed, or the element moved — the test fails and stops. The failure gets added to the morning report. An engineer investigates, identifies the root cause, updates the locator, and re-runs the test. That process takes time every single time it happens.
An AI self-healing system intercepts that failure at the moment it occurs. Instead of stopping, it analyses the page, compares the current state of the DOM against what it knows about the element from previous successful runs, and identifies the element that matches the expected behaviour and context — even though the specific identifier has changed. It updates the reference and continues the test.
The test still runs. The result is still meaningful. The engineer does not get paged. The morning report shows a pass, not a maintenance ticket.
The confidence is the problem — and why it matters
Most self-healing implementations have a limitation that reduces their practical value: they offer probable matches, not confirmed ones. When an element changes, the system identifies several candidates that might be the right element, assigns a confidence score to each, and presents the options for human review. The engineer still has to make the final call.
This is better than no healing, but it still requires human time. If the engineer is reviewing ten candidate suggestions per failure and you have fifty failures per run, you have not eliminated maintenance time — you have just changed what kind of work it involves.

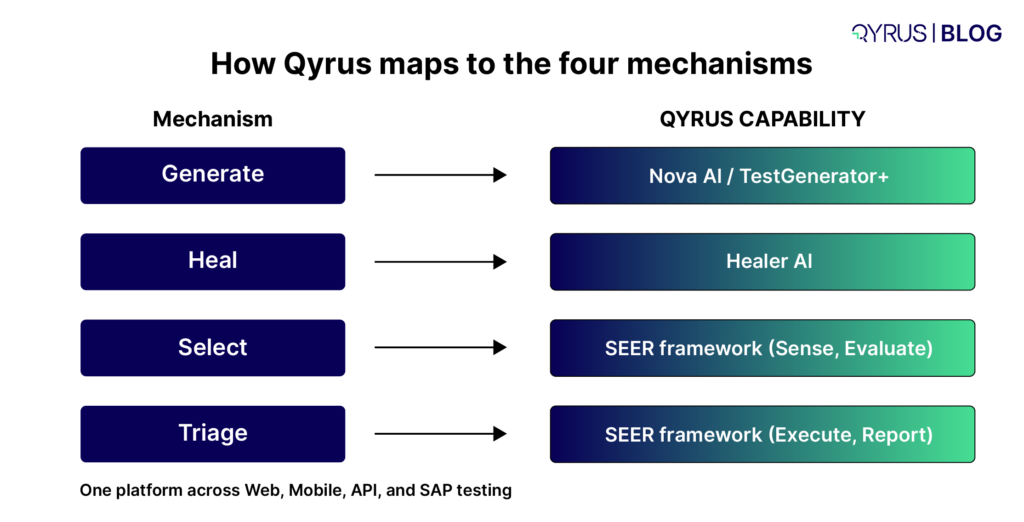
How Qyrus Healer approaches this differently
Qyrus Healer does not offer candidate matches with confidence scores. It does not return a value unless it has established with certainty that the element it has identified is functionally correct. The distinction matters operationally: when Healer identifies a replacement locator, the engineer does not need to review it, verify it, or decide between options. The correction is certain, not probable.
As Suraj from Qyrus’s client development team puts it: “Healer works on 100% certainty. It doesn’t provide a value unless it establishes functionality. Healer goes a step further than anything that’s out there.” Read the full conversation on healer here.
What that looks like
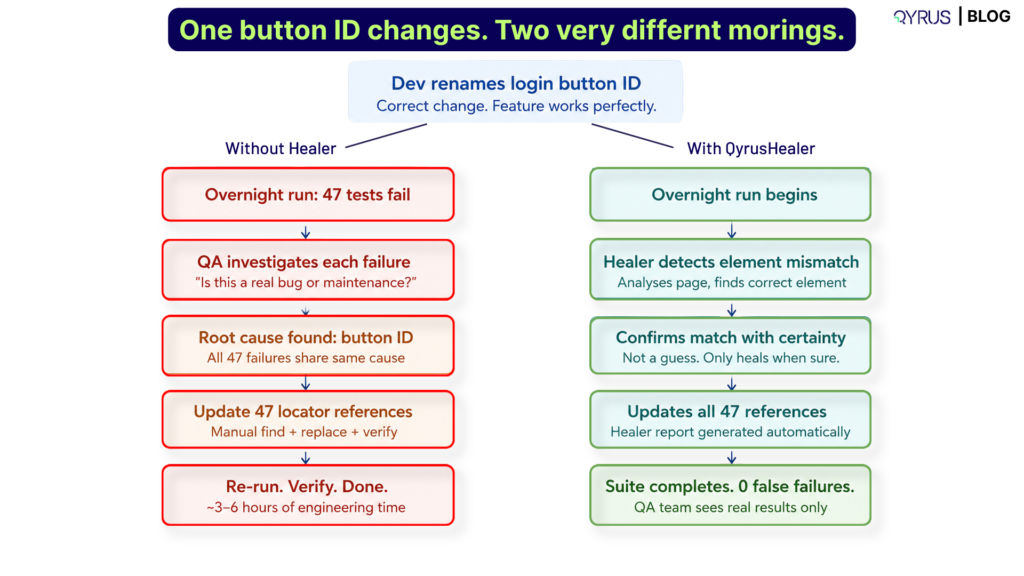
A team runs their regression suite overnight. During the day, a developer updated the ID attribute on the login button as part of a component refactor. The change was intentional and correct — the login feature works exactly as expected.
Without Healer: every test that touches the login flow fails with an ‘object not found’ error. The QA engineer’s morning starts with investigating which tests failed, confirming they all share the same root cause, finding the correct new ID value, updating every affected test, and re-running to verify. Depending on how many tests reference the login button and how many other changes were made in the same sprint, this takes hours.
With Healer: the test suite runs. When a test reaches the login button and cannot locate it by its old ID, Healer analyses the page, identifies the login button by its functional context and surrounding DOM structure, confirms it is the correct element, and updates the locator reference. The test continues. The suite completes. The morning report shows the actual state of the application — not a wall of maintenance failures.
Who benefits — it is not just testers
The impact of reducing test maintenance overhead extends beyond the QA team:
- QA engineers — less time on locator repair means more time on test strategy, coverage analysis, exploratory testing, and higher-value work that cannot be automated
- Developers — teams using Healer do not need to coordinate with QA every time they refactor a component or update element attributes. The tests adapt without intervention, which removes a friction point that slows down development velocity
- Business technologists and non-technical stakeholders — because Healer provides a detailed report of every healing event — what changed, what it was changed to, and why — business-side users can follow what is happening to their application’s test coverage without needing to understand automation internals
- Engineering managers — automation ROI improves when maintenance cost drops. A suite that was consuming a third of QA capacity on upkeep returns that capacity to work that creates value
What Test Flakiness Is Actually Costing Teams
Slower releases
When a regression run produces a large number of failures, someone has to triage them before the team can make a release decision. If that triage requires distinguishing between real defects and maintenance failures — and it does, because you cannot ship on a failed suite without knowing which failures matter — the release is on hold until the investigation completes. In teams running weekly or biweekly releases, this consistently pushes release dates.
Automation ROI that never materialises
The business case for test automation is a reduction in manual QA effort and faster release cycles. When a significant portion of the automation budget is consumed by maintenance rather than execution, the ROI calculations that justified the automation investment do not hold.
Teams that built automation expecting to reduce their QA headcount often find that the maintenance burden requires the same headcount — just doing different (and less valuable) work.
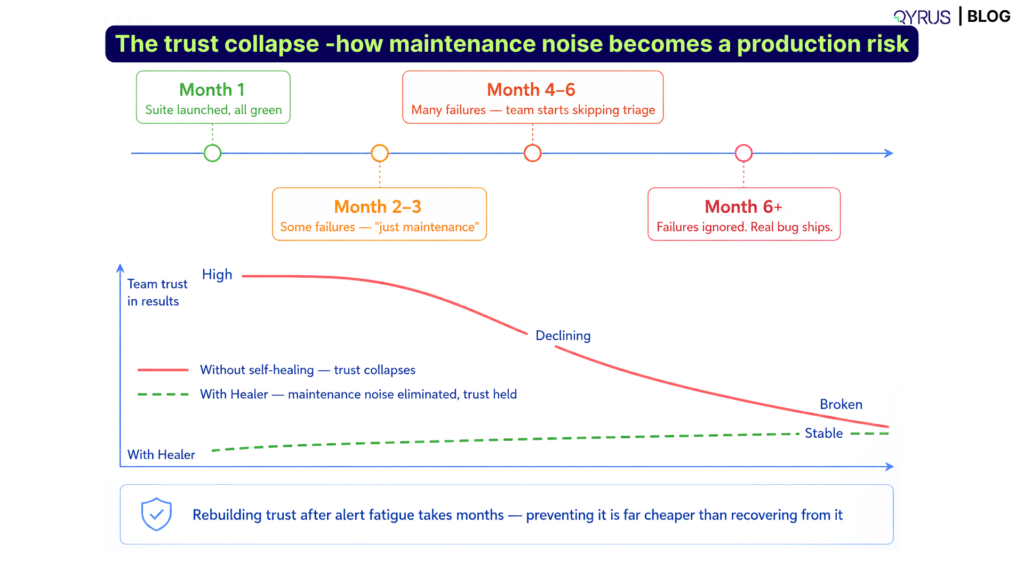
Alert fatigue and the trust collapse
This is the failure mode that is hardest to recover from. When a team’s CI/CD pipeline consistently produces test failures that turn out to be maintenance issues rather than real defects, engineers learn to discount failure reports. They stop investigating quickly. They start assuming failures are probably not real. And then a real defect ships because it was mixed in with maintenance failures and nobody looked closely enough.
Rebuilding trust in a test suite after alert fatigue has set in requires more than fixing the maintenance problem — it requires demonstrating to the team, over time, that failures now reliably mean something. That takes months.
Developer velocity issue
Every time a developer makes a legitimate, correct change to the UI and the test suite breaks, there is a cost: investigation time, coordination with QA, and sometimes rollback pressure if the maintenance cannot be completed before a deadline. Teams that have not solved the maintenance problem often find that developers start avoiding UI changes that are technically correct but ‘not worth the testing fight.’ The automation is actively constraining what the development team will build.
Qyrus Healer: What It Does and How It Fits Into Your Workflow
Healer is Qyrus’s AI-powered self-healing engine, built specifically to address the locator fragility problem that accounts for the majority of test maintenance effort. It works across both web and mobile automation, integrates with the existing Qyrus test suite, and operates without requiring manual review of its corrections.
How Healer works
When a test encounters an element it cannot locate using its existing selector, Healer activates. It analyses the current state of the application, cross-references it against the element’s known functional context and historical locator information, and identifies the correct element with certainty before updating the reference. The test then continues from that point.
Healer does not use a probabilistic matching approach that presents options. It identifies the correct element definitively, or it does not offer a correction at all. This means the corrections it makes do not require human sign-off — they are implemented with the same confidence as a manually verified locator update.
What Healer reports back
Every healing event generates a Healer report that logs exactly what changed: the original locator value, the new locator value, the test case and step affected, and the element on the application that was updated. This reporting serves two purposes: it creates an audit trail for teams that need to track what is happening to their test suite over time, and it gives business technologists and non-technical users visibility into the health of their automation coverage without requiring them to read test code.
Where Healer applies
Healer works across the Qyrus platform’s full testing scope — web automation and mobile automation — which means the same self-healing capability that covers your web UI tests also covers your native iOS and Android tests. In mobile testing, where element identifiers shift frequently between OS updates, device variants, and manufacturer customizations, self-healing has a particularly high impact on maintenance reduction.
What Healer is not
Healer does not fix tests that are failing because of real application defects. If a button is broken, Healer will not make the test pass — it will report the failure accurately. Self-healing addresses the false positive problem: tests that fail because of element changes, not because the application is broken. When a failure is real, it surfaces as a real failure. This is the distinction that makes Healer useful rather than dangerous — it reduces noise without hiding signal.
Forrester and Gartner recognition
Qyrus was named a Leader in the Forrester Wave for Autonomous Testing Platforms (Q4 2025), with the highest scores in Roadmap, AI Testing Dimensions, and Agentic Tool Calling. Forrester cited Qyrus for advanced AI-driven testing and multiagent orchestration. Qyrus is also featured as an AI-Augmented Testing vendor in Gartner’s April 2025 report on generative AI in the software delivery lifecycle.
What to Actually Look for When Evaluating AI Self-Healing Tools
Self-healing has become a marketing term that many testing tools claim. Before adopting any solution, there are specific questions that distinguish implementations that reduce maintenance cost from ones that simply rename the problem:
Does it heal with certainty or with probability?
Probability-based healing — where the system offers candidate matches and the engineer chooses — still requires human time. Certainty-based healing — where the system identifies the correct element definitively and applies the correction without review — is the version that actually eliminates maintenance hours. Ask vendors to demonstrate what happens when an element changes: does the tool fix it automatically, or does it surface options for a human to approve?
Does it work on both web and mobile?
Element fragility exists on both platforms, and the mobile version of the problem is arguably worse because of OS updates, manufacturer-specific rendering, and the speed at which mobile frameworks evolve. A self-healing solution that only covers web automation leaves the mobile maintenance problem intact.
What does the reporting look like?
Self-healing without reporting creates a different problem: your tests are passing, but you do not know why locators keep changing. Good self-healing tooling provides a complete audit trail of every healing event — what changed, when, in which test, and to what value. This is what allows teams to monitor UI change patterns and understand whether the healing is covering legitimate application evolution or signalling a more systematic problem.
Does it introduce false positives on the other side?
A self-healing system that is too aggressive will make tests pass when they should fail — by identifying a ‘close enough’ element that is not actually the right one. This is worse than the original maintenance problem, because it creates false confidence. Ask specifically how the tool handles ambiguous cases: does it heal when uncertain, or does it fail the test and report that it could not identify the correct element with confidence?
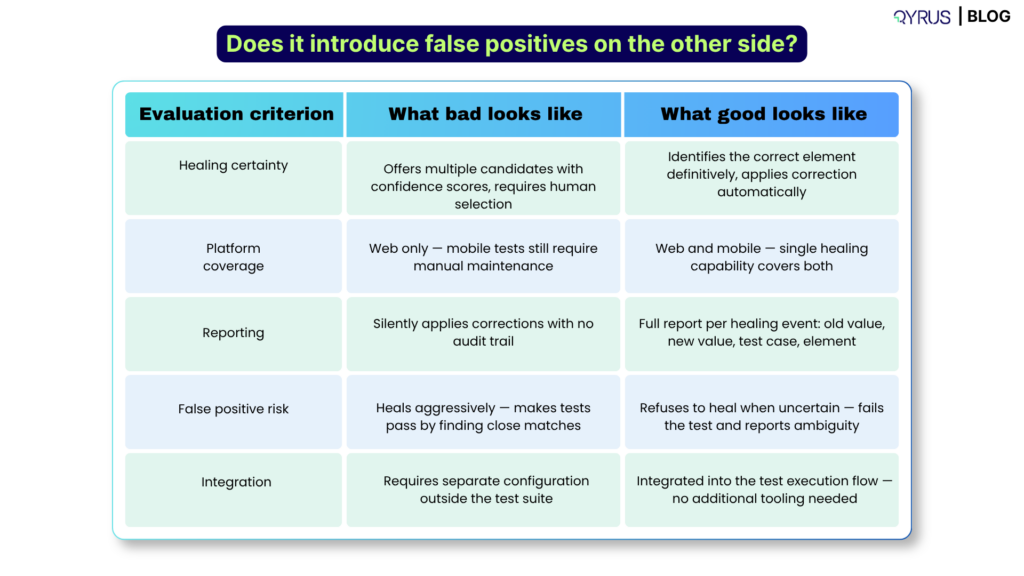
Evaluation criterion | What bad looks like | What good looks like |
Healing certainty | Offers multiple candidates with confidence scores, requires human selection | Identifies the correct element definitively, applies correction automatically |
Platform coverage | Web only — mobile tests still require manual maintenance | Web and mobile — single healing capability covers both |
Reporting | Silently applies corrections with no audit trail | Full report per healing event: old value, new value, test case, element |
False positive risk | Heals aggressively — makes tests pass by finding close matches | Refuses to heal when uncertain — fails the test and reports ambiguity |
Integration | Requires separate configuration outside the test suite | Integrated into the test execution flow — no additional tooling needed |
Conclusion
The test maintenance problem is not going away on its own. Every sprint that ships UI changes produces new maintenance work. Every expansion of the test suite creates more surface area for that work to compound. And every hour a QA engineer spends updating locators instead of finding defects is an hour the automation ROI calculation moves in the wrong direction.
AI self-healing does not fix every part of this problem — it does not address flakiness caused by timing, or failures caused by real defects, or the strategic question of which tests to write. What it does address is the single largest category of test maintenance cost: tests breaking because identifiers changed, elements moved, or labels were updated, when the underlying functionality is completely intact.
When that category of failure is handled automatically, the morning report becomes meaningful again. Engineers investigate failures that represent real problems. Releases do not wait on locator triage. The suite grows in coverage without growing proportionally in maintenance burden.
Request a demo to see how Qyrus Healer can reduce your test maintenance overhead and give your QA team back the time they are currently spending keeping broken tests alive.