LLM Evaluation: How Enterprises Validate AI Outputs Before They Reach Users
 Varun RS
Varun RS

Enterprises rush to deploy Large Language Models (LLMs) to gain a competitive edge. However, speed without control invites disaster. One incorrect answer in a customer support portal or a security flaw in AI-generated code can lead to legal action or a data breach.
We know that quality assurance defines the success of any software deployment. AI requires even stricter standards. You must treat AI output validation as the steering wheel of your innovation, not the brake pedal.
Current data highlights a massive gap in enterprise readiness. While healthcare data breaches affected over half the U.S. population in 2024, only 31% of organizations actively monitor their AI systems. This lack of oversight exists. It persists despite evidence that regular assessments triple the likelihood of achieving high value from GenAI.
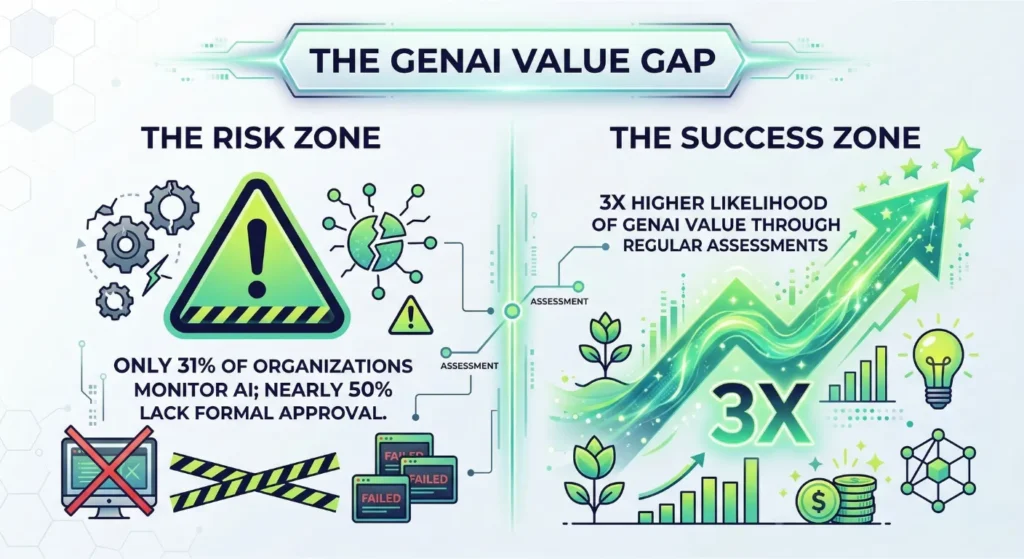
Organizations must implement robust LLM evaluation to bridge this safety gap. You protect your brand only when you prioritize generative AI testing throughout the model’s lifecycle.
Why Is Simple Keyword Matching Failing Your AI Strategy?
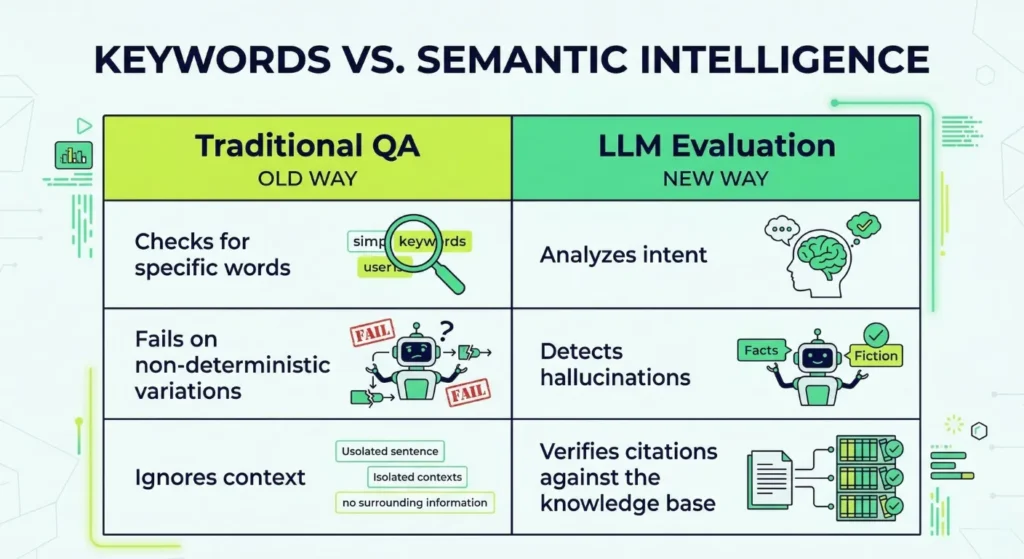
Traditional software testing relies on predictable, binary outcomes. If you input X, the system must return Y. LLMs behave non-deterministically. They produce thousands of variations for the same prompt. This unpredictability creates a massive challenge for AI output validation. If your quality assurance team relies solely on keyword matching, they will miss subtle but dangerous errors.
Effective LLM evaluation rests on three key pillars:
- First, you need deep semantic analysis. You must verify that the AI captures the user’s intent rather than just repeating terms.
- Second, rigorous hallucination detection in LLM is non-negotiable. You must confirm that every claim the model makes exists within your trusted knowledge base. Industry analysts expect the market for these observability platforms to reach to about USD 8.07 billion by the early 2030s as companies prioritize safety.
- Finally, every response needs citation integrity. If an AI provides financial advice or technical specs, it must link back to a verified source. High-performing teams that automate these checks often see a 25% improvement in complex query accuracy.
Is Your Generative AI Testing Covering the Whole Architecture?
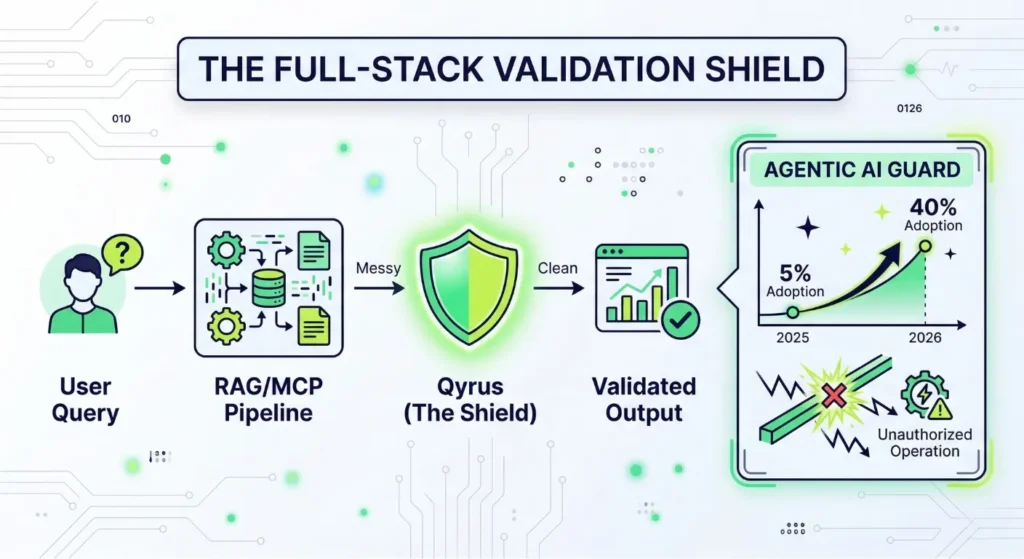
Many teams make the mistake of only checking the model’s final response. This narrow focus misses the technical cracks in your underlying architecture. Enterprise-grade generative AI testing must validate the entire stack. This includes your Retrieval-Augmented Generation (RAG) and Model Context Protocol (MCP) pipelines.
Qyrus runs deep system-level checks to expose failures that surface-level reviews ignore. You must ensure your retrieval layer gathers the correct context before the model even starts writing.
Agentic AI introduces even more complexity as autonomous systems take actions on your behalf. Industry forecasts suggest that enterprise applications using task-specific agents will surge from less than 5% in 2025 to 40% by the end of 2026. Without a robust LLM testing strategy that handles autonomous behavior, these agents might perform unauthorized operations.
Qyrus provides an Agentic AI Guard to keep these systems within defined bounds. It verifies tool selection and blocks risky actions in real-time. Our AI Quality Suite achieves over 98% faithfulness in validated outputs. This level of precision ensures your agents remain reliable as they scale across your organization. Consistent LLM Evaluation ensures your AI stays on-task and secure.
How Do You Audit an AI That Never Gives the Same Answer Twice?
Traditional testing fails when your software generates unique text for every single user. You cannot write a manual test case for every possible sentence an LLM might produce. Instead, you must build a system that understands intent and accuracy.
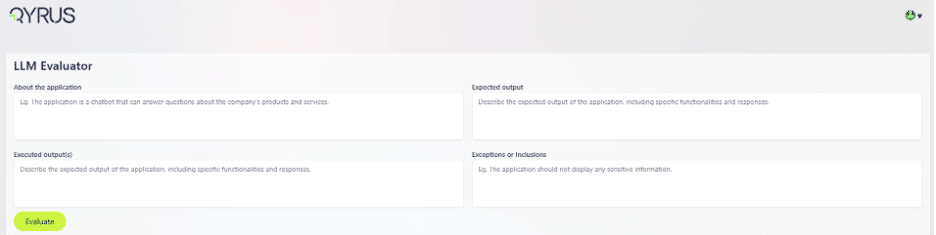
Qyrus LLM Evaluator simplifies this complexity by providing a structured framework for generative AI testing. You begin by defining the “About the Application” section to provide the evaluator with context. Then, you establish the “Expected Output”—your gold standard for what the AI should ideally say.
The real power lies in defining “Exceptions or Inclusions.” For example, you might command the bot to never disclose account balances over one million dollars or to always include a specific legal disclaimer.
You then input the “Executed Outputs” from your model. The system instantly analyzes the response, providing a relevance score from one to five and a detailed reasoning for that score.
Can Your Team Scale LLM Evaluation Without Losing Precision?
Automation is the only way to keep pace with rapid model updates. Manual reviews simply take too long and introduce human bias. A robust LLM testing strategy uses a “judge” model to verify the primary model’s work. It checks for specific positives and negatives in every response. Did the bot mention the account balance? Did it follow the formatting rules? The evaluator answers these questions in seconds.
By automating your AI output validation, you achieve a level of consistency that human auditors cannot match. This automated layer provides a safety net that catches errors before they reach your customers. It handles the heavy lifting of hallucination detection in LLM by cross-referencing every generated claim against your source documents.
When you integrate this into your CI/CD pipeline, LLM Evaluation becomes a continuous process rather than a final hurdle. You gain the confidence to deploy updates daily, knowing your guardrails remain intact and your brand remains protected.
How Does Industry Context Change Your Validation Strategy?
Enterprise risk shifts significantly depending on your field. A typo in a blog post might be embarrassing, but a mistake in a medical summary or a legal contract can destroy a company. You must tailor your AI output validation to the specific regulatory and operational pressures of your vertical.
Will Your Internal Assistant Accidentally Violate Labor Laws?
Internal HR bots often handle sensitive employee data and policy inquiries. If your AI provides incorrect guidance on overtime pay or hiring practices, you face immediate legal exposure. Quality engineering teams must implement LLM testing to verify that every response stays within corporate and legal guardrails.
We focus on automated auditing that cross-references AI suggestions against current labor regulations. This prevents the model from exposing personally identifiable information (PII) or suggesting discriminatory practices. Rigorous LLM Evaluation ensures your internal tools protect your employees and your legal standing.

Could a Helpful Chatbot Cost You $11,000 in a Single Transaction?
Ecommerce brands often prioritize a “polished” tone, but tone without accuracy creates merchant liability. One chatbot famously offered an 80% discount without any human approval. The resulting order totaled nearly $11,000. This is a real risk. Generative AI testing identifies these outliers by running thousands of simulated interactions before you go live.
You must ensure your bot hits 95% accuracy against your live product manuals and pricing sheets. We use automated judges to flag any unauthorized promises, ensuring your AI remains a sales asset rather than a financial drain.
Is Your Clinical AI a Multi-Million Dollar Liability Waiting to Happen?
Healthcare and finance demand the highest levels of precision. In 2024, data breaches affected over half the U.S. population. Regulators now levy penalties exceeding $2 million annually for HIPAA failures. Meanwhile, financial compliance officers spend over 30% of their week manually tracking enforcement actions. You can automate much of this oversight.
We implement deep hallucination detection in LLM to ensure clinical summaries or financial advice match verified source documents perfectly. Our platform achieves over 98% faithfulness in these high-stakes environments. This level of control allows you to innovate without fearing a regulatory crackdown.
Why Automated LLM Testing Is the Key to Your Enterprise Growth
Software quality defines the modern business. Generative AI testing simply extends those rigorous standards to the next generation of applications. Organizations that conduct regular assessments significantly increase the likelihood of extracting high value from their AI investments. You cannot afford to deploy models that act as black boxes. Qyrus and our LLM Evaluator transform these systems into transparent, reliable assets.
We believe that quality functions as the steering wheel for your innovation. Our AI Quality Suite automates the most difficult parts of LLM Evaluation and AI output validation. We achieve over 98% faithfulness in validated outputs, allowing your team to move at high velocity without fear. Robust hallucination detection in LLM turns your AI from a liability into a competitive edge. It is time to move past experimental pilots and into governed, measurable operations.
Secure your enterprise AI today. Reach out to the Qyrus team to schedule a demo and see how our platform safeguards your future.
Frequently Asked Questions
How to detect hallucinations in LLMs before they reach your customers?
You must implement an automated judge that cross-references AI claims against your internal documents. Qyrus uses semantic comparison to identify assertions without evidence. This automated hallucination detection in LLM saves hundreds of manual auditing hours. It ensures every response stays grounded in your data. Relying on human reviewers for thousands of logs is impossible.
Which LLM response validation methods offer the highest accuracy?
Semantic scoring outperforms simple keyword matching. You should use LLM response validation methods that assign a score (1-5) based on relevance and faithfulness to the source. Our LLM Evaluation framework provides clear reasoning for every grade. This helps your team identify why a model failed and how to refine the prompt.
Why is automated testing for generative AI essential for scaling?
Manual testing cannot keep up with models that update frequently. Automation lets you run thousands of test cases in a single afternoon. Teams that use automated testing for generative AI reduce production time by 50% and see a 30% improvement in data extraction accuracy.
What are the best tools for LLM evaluation on the market today?
You need a platform that validates the entire architecture, not just the output. Qyrus Pulse and the LLM Evaluator provide full-stack visibility. We offer the precision required for enterprise-grade LLM testing. Our suite handles everything from simple chatbots to complex autonomous agents.
How should your team approach validating LLM outputs for enterprise AI?
Start by defining your “Expected Output” and “Exceptions or Inclusions.” This establishes the rules for the AI. You then compare the “Executed Output” against these rules. Since only 31% of organizations monitor their AI, validating LLM outputs for enterprise AI gives you a major security advantage. It prevents brand liabilities before they happen.
What is the most effective way of testing RAG pipelines?
You must run system-level checks on the retrieval layer and the prompt assembly. Testing RAG pipelines involves verifying that the vector search gathered the correct context. Qyrus Pulse exposes failures that surface-level reviews miss. We ensure your RAG system achieves over 98% faithfulness to the original source.
How to test AI chatbots for legal and financial risks?
Run adversarial simulations to see if the bot violates your internal policies. How to test AI chatbots requires setting clear “Negatives”—things the AI should never do. For example, you might block the bot from revealing account balances over a certain limit. This type of AI output validation stops costly errors in their tracks.
Are there specific AI compliance testing tools for regulated sectors?
Yes, you need tools that specifically address HIPAA and financial regulations. Regulated sectors face penalties exceeding $2 million annually for privacy failures. Qyrus offers specialized AI compliance testing tools that automate the auditing of clinical and legal outputs. We keep your AI within the strict bounds of the law.
 March 9, 2026
March 9, 2026  9 min
9 min